Fake news detection
I’m introducing my automative fake news detection machine learning project. Since there is no concensus theory in detection of fake news solely based on news contents, for both human and machine sides, my perspective and conjectures are reflected in this project, which makes this project more fun. The final model showed good performance, 95% accuracy. The limitation of performance of this model, as well as pitfall in evaluation is discussed. Besides, interesting idea to test is suggsted at the end.
Any comment is welcome. Feel free to share your idea.
Visit my GitHub to see the codes
1. Intro
1.1. Motivation of automatic fake news detector
For the last few years, fake news has been an emerging threat to democratic communities globally. Although fake news is not a new thing, as more and more people get to rely on digital news flatform than traditional ones recently, fake news has been even more efficiently spread possessing advantages of the digital media, which is fast, massive, and personalized. Due to the high data volume of fake news, automated fake news detection software has been desired, and vigorous studies to develop such software are ongoing.
1.2. Difficulties of automatic fake news detection
Fake news detection is an open study area. Although there are many existing models, including a simple model that achieved 99% accuracy and a complicated model that achieved 70% of accuracy, there seems no agreement about efficient machine learning architecture, evaluation method, and data mining, and some analogous opinions about useful features. The main difficulties can be categorized into two: absolute reason and practical reason.
1.2.1. Absolute reason
Fundamentally, no one can rationally infer whether a new is true or false solely relying on its text contents. For an extreme and hypothetical example, if you change some dates and names in real news, there’s no way you can tell the news is incorrect. Indeed, many fake news mokes or quotes real news, which makes it hard to tell difference. A machine wouldn’t infer either. The way how we judge whether to trust a piece of news is not only based on the text contents, but also the credibility of the source, such as a media company, a writer, or cross-checks. Because of this reason, some researches attempt to include not only the news contents but also the author information in their machine learning model.
1.2.2. Practical reason
Another difficulty is in the machine learning aspect, specifically, the potential bias of datasets. In a dataset collected, real news and fake news might cover different topics. Then the machine has the potential to learn classification relying on topics, rather than more essential characters of real and fake news. For example, if the word “flat earth” appeared in your fake news dataset only, although your model has a high test accuracy with your dataset, this model has the potential to mark all real news as fake if the real news is about concern about “flat earth” believers. In other words, you wanted a machine that classifies between real apples and fake apples, but your machine turned out to classify between apples and oranges. Because of this reason, some researchers focus on training fact-checked fake news as fast as possible, so that the fake news topic can be up-to-date for their machine.
2. Project idea
2.1. Distinct characteristics of fake news text
As in the above, discerning whether a news article is true or not based solely on its text is difficult. However, in my opinion, it might not indicate that real and fake news classification is impossible, due to distinct characteristics that fake news cannot give up: marketing (see the summary of known characteristics of fake news can be summarized as in the appendix).
The purpose of news is to inform important or irregular businesses speedily and accurately. Therefore, news articles are written in a concise and comprehensive manner. On the other hand, the purpose of fake news is an advertisement: fake news is written by a particular force to increase their political or economical benefit. To serve such goal, fake news should be written to make a specific demographic group to 1) notice and read their news, then 2) create some emotion, which leads them to 3) do some action.
Then one can guess that for item 1) in the above paragraph, the title of fake news has a clickbait or exciting words to induce users’ click, and such titles must be deliberately engineered considering item 2) and item 3). Indeed, such patterns can be easily noticed in the following examples of real and fake news titles in the dataset I used.
Example of real news titles:
“South Korea’s Moon unveils new focus on Southeast Asia”
“U.S. presidential race tied, Clinton hurt by emails: poll”
“Kenya High Court rules minor candidate should be on ballot for poll re-run”
“Swiss strip refugee status from Libyan preacher”
“Iowa moves to cut Medicaid funding for Planned Parenthood”
Example of fake news titles:
“BREAKING: Evidence Trump Cheated Leads To MASSIVE Move For Three State Audit”
“BOOM! LIBERAL COLUMNIST Gets DESTROYED By Tucker Carlson When He Can’t Answer Why He Lied About Senator Jeff Sessions [VIDEO]”
“An OBAMA “LOW LEVEL OFFENDER” Gets Early Release From Prison: Brutally Murders Woman, Slits Throats of 7, 10 Yr Old Daughters”
“BREAKING: TED CRUZ WINS IOWA NOT-SO-SLICK WILLY: Bill Clinton Tries To Joke Around About Hillary’s E-mail Scandal…Not Funny [Video]”
“VP Of Trump Transition Team To Dems: ‘Put Your Big Boy Pants On’ And Attend Inauguration (VIDEO)”
2.2. Project idea
The real news titles are concise and comprehensive, whearas fake news titles look more emotional and inflammatory, as well as some of them contain teaser words (“Video, image, details…”), which induce click. Such difference can reduct a classification between true and fake news into a sentiment classification problem. From this perspective, then automatic news classification based on the title text might be a feasible machine learning project. Motivated by sentimental language classification models, this project utilizes several machine learning models and news titles of available dataset.
3. Analysis
3.1. Dataset
The dataset is provide by Information Security and Object Technology (ISOT) research lab, University of Victoria. Link
The dataset contains 21k of real news scrapped from “Reuters.com” and 24k of fake news collected from different sources, where all of them are flagged as unreliable by Polififact (a fact-checking organization in the USA) and Wikipedia. The coverage of topics are various, yet mostly about politics.
Provided dataset are True.csv (reuter news) and Fake.csv (unreliable news), where title feature was used for this model. For any training process, equal number of randomly selected news were used for both true and fake news.
3.2. EDA and text preprocessing
EDA was done to find text preprocessing items and distinctive features between real and fake news. Followings are selected findings of fake news features (see full findings in the github repo).
- Longer titles (see the below histogram of word count)
- Noisy texts (more usage of special characters)
- Contains improper words, combined with special characters (e.g. f*ck)
- Clickbait: Not enough information while implying complementary visual information (e.g. “video”, “image”)
- First name appears (Donald, Hilary)
- Emotional, with exclamation marks (!, ?)
- Somewhat different in grammar structure, but hard to tell what it is specifically
- Not consistent in expression/format (e.g. U.S. is written in several formats, such as U.S., U.S.A. etc) Such features are opposed to characteristics of news, which is concise, comprehensive, and objective.
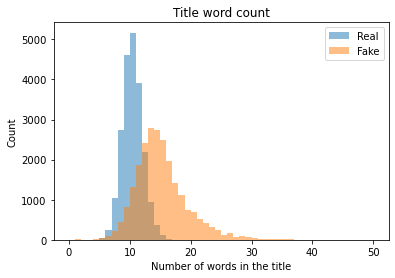
Those features were considered in text preprocessing. Text preprocessing includes unifying format/abbreviation (e.g. U.S., US, U.S.A to U.S.), tagging swearing words, removing noise and stopwords, and lemmatization. To test the effect of noise level, models with less preprocessed text inputs were tested as well.
In addition, utilizing found features, a simple manual model was built in this step in order to provide a baseline performance score. This simple model selects events that contain those features. As a result, this model showed surprisingly high precision of fake news, accuracy was not better than 50% because not all fake news is explained with those features, which a human could notice easily.
3.3 Word encoding and input
Preprocessed texts were encoded using Glove-6B word embedding to be inputs of machine learning models. In addition, with anticipation that machines can learn different “feelings” of grammar structure between real and fake news, part-of-speech (PoS) tags of title words were used as input after one-hot encodings. The following are summarized five kinds of inputs of the machine learning models.
- Glove word embeddings, done to
- “org_title (og, Original)”: Raw text, which includes all noise
- “lower_title (lo, Lower)”: Lower cased raw text
- “cleaned_words (cw, CleanWord)”: Preprocessed text, without stopword removal and lemmatization
- “minimal_words (mw, MinimalWords)”: Preprocseed text, after stopword removal and lemmatization
- One-hot encodings, done to
- “cleaned_pos (ps, PoS)”: part-of speech taggings of “cleaned_words” text
3.4. Machine learning model
The model applied the ensemble learning method. For an ensemble method, bagging was used because it is strong in overfit. The ensemble model is composed of Naive Bayes, Long Sort-Term Memory (LSTM), and Feedforward Neural Network (FNN) architectures. Those models were selected due to following reasons.
- Naive Bayes: simple, fast, and widely used in text classification
- LSTM: good performance in sequantial data
- FNN: used on averaged encoded vectors with a conjecture that each of real and fake news shares some vector components
In total, 15 (3 machine learning architectures x 5 kinds of input) models were trained with 23k of randomly sampled data. Sampling allowed duplication. Deep learning models (LSTM and FNN) were optimized with Adam for efficient gradient descent. Three hidden layers were chosen with belief that this number can keep the network size small while not losing flexibility. Since models showed good performance, coarsely tuned parameters were kept. Dropout and early stopping were applied for fast regularization. Hyperparameters (learning rate, batch size, number of hidden units, and dropout rates) were tuned coarsely due to limited computing power.
Finally, those 15 trained models combined to the one final model. The final model is trained with the bagging ensemble learning to reduce overfit. Those 15 models served as weak classifiers of the final ensemble model. This final model predicted output with the vote of 15 trained models with equal weight.
4. Conclusion
4.1. Performance of weak classifiers
The below figure shows performance scores of each weak classifier model.
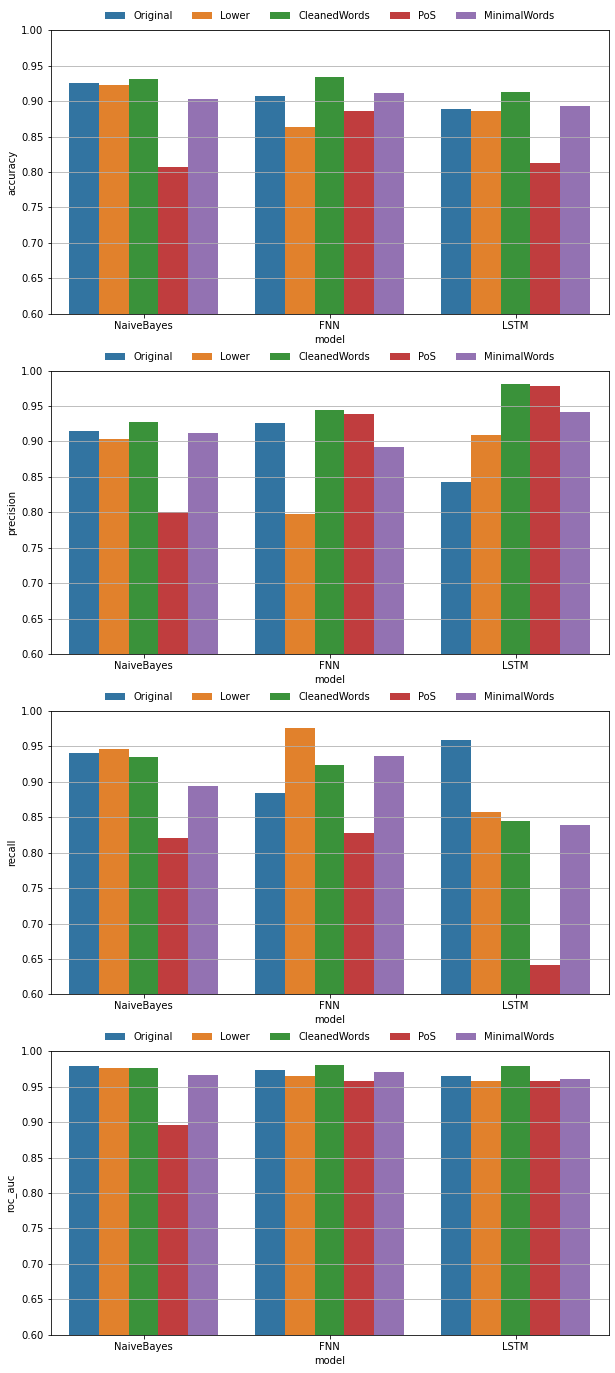
Each plot displays different score metric, accuracy, precision, recall, and roc auc (integrated roc curve). Three chunks in each plot represents different machine learning models, Naive Bayes, FNN, and CNN. Different color corresponds to the different input. Observations are:
- Each model showed accuracy over 80% while showing a high correlation in prediction between models.
- “CleanWord” input models performed better than “MinimalWord” models. Indeed, removing stop words disimproved the performance. It implies that not only the meaningful words, but also the complete sentence structure plays important role in classification.
- “PoS” input models have low recall score. It can be a hint that a lot of fake news mock grammar structure of real news, therefore, detecting them soly by grammar structure is not efficient.
- LSTM with “CleanWord” or “PoS” inputs had the highest precision, means good at rejecting real news. On the other hand, these models were the lowest in recall, means bad at collecting fake news.
- There’s no single machine learning model or input type that wins or loses everywhere.
- AUC values (area under the ROC curve) are high for all models. It implies that these models can serve good fake news detector without too much cost from false alarm. The plot in the below shows the ROC curve and the prediction probability (softmax output) distribution of real and fake news of one model (LSTM, PoS input).
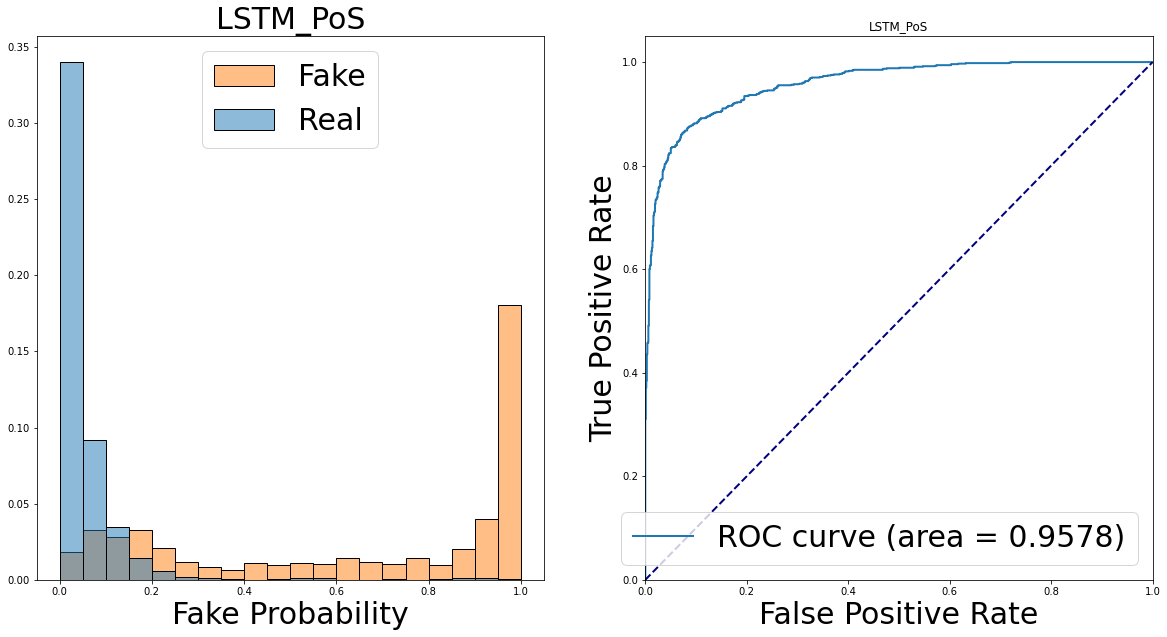
4.2. Performance of the ensemble model
The final model showed good performance. The accuracy, recall, and precision were about 95%. Correctly and incorrectly classified examples are shown in the below. Can you do better job than this machine (can you tell which news is fake by reading its title only)?
True Negative (real news, predicted real):
- ‘With or without Democratic director, U.S. consumer watchdog to be weakened’,
- ‘As Brexit clock ticks down, EU eyes new offer from May’,
- ‘House Freedom Caucus chief calls for U.S. tax reform plan by end-July’,
- “Russian presidential hopeful says she won’t sling mud at Putin”,
- ‘Wealthy donors drawn to Rubio White House bid after Bush drops out’
True Positive (fake news, predicted fake)
- ‘NSC WILL NOT Fulfill Subpoena Request For Susan Rice Unmasking Documents…Records Moved To Obama Library…Presidential Records Act Keeps Them Hidden From Public For 5 Years [VIDEO]’,
- ‘TRUMP MIC DROP MOMENT From 60 Minutes Interview: “I’m very good at this, it’s called construction”’,
- ‘WATCH: Trump Campaign Manager Lies About Abortion, So Anderson Cooper Humiliates Her With Facts On The Air’,
- ‘OBAMA CONDEMNS TRUMP…Says U.S. Is “Blessed With Muslim Communities”’,
- ‘McCain RIPS GOP Brass Over Russian Hack Response, Accuses Them Of Threatening Democracy (VIDEO)’
False Positive (real news, predicted fake)
- ‘How Ted Cruz win in Supreme Court hurt U.S.-Mexico relations’,
- ‘Before New Hampshire primary, Trump campaign shows mellower side ‘,
- ‘Dying for a paycheck: the Russian civilians fighting in Syria’,
- ‘Struggling Republican Bush brings out the big gun: his mom’,
- ‘Trump attends ‘Villains and Heroes’ costume party dressed as…himself’
False Negative (fake news, predicted real)
- ‘Alabama Republican House Speaker Removed From Office, Convicted On Ethics Violations’,
- ‘House Committee Uncovers DAMNING BOMBSHELL – Russia PAID Michael Flynn To Appear With Putin’,
- ‘MILITARY LEADERS SPEAK UP: IRAN DEAL MAKES WAR MORE LIKELY’,
- ‘CONGRESSMAN SOUNDS ALERT TO CYBER SNOOPING LAW SNUCK INTO BUDGET BILL’,
- ‘Caroline Kennedy Is Eyeing A White House Bid’
Before move on to the next session, let’s check a correlation between weak models to get an insight of potential improvement. This is the heat map of the pearson r value between predictions of two models (read the machine learning model names and input tag and ignore “_p1” at the end).

All models have high correlation with each other except those with PoS inputs. Then let’s see a few examples where the ensemble model is wrong, but the LSTM PoS input model is right.
False Positive, but PoS predicted Negative:
- ‘Struggling Republican Bush brings out the big gun: his mom’,
- “Live from New York, it’s a Trump-Clinton rematch - of sorts”,
- ‘U.S. might ban laptops on all flights into and out of the country’,
- “Hands off EU, Trump; we don’t back Ohio secession: Juncker”,
- “Despite undiplomatic discourse, Trump’s dance card is full”
False Negative, but PoS predicted Positive:
-‘OBAMA REGIME’S SECRET ASIAN TRADE DEAL Would Let International Tribunal Overrule State and Fed Laws To Benefit Foreign Companies’,
- ‘STOCKHOLM STUDY: US & Europe Top Arms Trade Globally – Saudi Arabia’s Weapons Imports Skyrocket Over 200 Percent’,
- ‘SYRIA CEASEFIRE? Lavrov, Kerry Agree to Fight Al-Nusra, No Strikes on ‘Rebels,’ Aleppo Relief’,
- ‘JUST IN: Helicopter Crashes In Saudi Arabia KILLING 8 High-Ranking Officials Only One Day After Saudi King ARRESTS Trump-Hating Billionaire And Dozens More Cabinet Members’,
- ‘NIGEL FARAGE ON TRUMP/MERKEL POWWOW: Merkel’s decision for mass migration the “worst decision by European leader in 70 years” [Video]’
It seems the ensemble model has a tendency to predict fake (real) news with short (long) titles as true (false), and PoS input model predicted some of such case correctly, interestingly.
4.2. Discussion
4.2.1. Scope and limitation
This project analyzed titles of professional news media articles, which follow traditional newspaper format. All of the real news came from the Reuter, there can be bias from limited news media. For example, this model might not perform well on real news with a casual tone, which is fond of social media. However, such casual news often quote professional news article, and professional articles are similar to Reuter news in tones and format, so limitation in dataset might be overcome by adding automatic search of the news source in casual news input.
Although this model achieved 95% of high performance, the test score of fake news might be a bit arbitrary regardless of how good one model is, due to the reason mentioned in section 1.2.2. Since fake news handles specific topics, any bias introduced from non-overlapping topics between real and fake news is not perfectly separable from model performance. From EDA, this dataset also has non-overlapping topics between real and fake news.
Most frequently appearing words in real news, but never appears in fake news:
- Prime minister
- South
- Brexit
- Seek
- Fackbox
- Source
- Urge
- Turkey
- U.K.
- Sanction
- Myanmar
- Trade
Most frequently appearing words in fake news, but never appears in real news:
- Breaking
- GOP
- Slangs (e.g. f*ck, a\@\@)
- Liberal
- Racist
- Lie
- Cop
- Like
- Image (in paranthesis at the end of the title)
- Old
- Terrorist
- Wow
- Bernie
It seems international topics are less shown in our fake news dataset, so this model might classify articles with international topic as real. Such bias is the nature of fake news, however, in real-life practice. From this reason, the best solution might be keeping a model up to date by training it whenever new fake news appears before it spread too much.
4.2.2 Further study idea
To verify the potential effect of our limited dataset, an interpretability study will be desired. Since all deep learning models have correlation with the Naive Bayes models, its straightforward interpretation can be useful for the combined final model. LIME or SHAP would give local interpretation of each title example. Such study will provide understanding and evidence of reliability of this model.
Extracting word vector component of real and fake news, and find synomyms might be interesting. Since FNN model with averaged vectors showed high performance, finding such vector components is feasible. Existance of close words of those vector components are questionable though.
Finally, I’d like to throw an interesting idea to study: whether “they find fake news, or fake news find them”. In marketing, the psychological and behavioral patterns depend on demography, so advertisements are customized for each targetting group. Meanwhile, the target demography of fake news is not a secret. If you split the whole people in a country using discriminative demographic features, you will notice that they are the major population group of the country or the swing voters of the country. Therefore, it will be interesting to analyze if fake news shares features of advertisement strategy on such group on purpose. Clustering analysis might work if dataset is available. If this idea turned out to be correct, tons of fake news believers are rather victims than assailants.
5. Further readings
-
Truth of Varying Shades: Analyzing Language in Fake News and Political Fact-Checking (Rashkin et al., EMNLP 2017)
-
Automatic Detection of Fake News (Pérez-Rosas et al., COLING 2018)
-
Fake News Detection on Social Media: A Data Mining Perspective (Kai Shu et al., SIGKDD Explor. Newsl. 2017)
-
CSI: A Hybrid Deep Model for Fake News Detection (Natali Ruchansky et al., CIKM ‘17)
-
Various sources about fake news and marketing theories
A. Known characteristics of fake news
I summarized the judging criteria about credibility of news into three categories.
-
Information-wise
-
Lack of information
- Not comprehensive
- Lack of context, not the whole truth
-
Not a NEWs
- Outdated story
-
Not valuable
- Not impactful/important socially
- Not a rare event
- Nothing to do with the area where the news provider covers
-
-
Tone
-
Doesn’t sounds professional
- Contain slangs
- Vocabularies are not concise and clear
-
Hateful
- Enhance bias or discrimination
- Provocative
-
Urgent and Agitative
- Make readers to spread this news as much as you can
- Make reader to act promptly
-
Joke (or pretend to be a joke)
- Make fun of someone/organization/policy
-
Clickbait
- The title contains the above
-
-
Source-wise
-
Author
- Cannot find the name of author
- The author is fake
- The author is not a reliable person/organization
-
Media/Publishing organizatio
- The media is not reliable of fishy
-
Supporting evidence
- The evidence that support the news is not adequate
- Not provided by a relavant expert or organization
-
Leave a comment